`
| |
|
Thursday, June 19th, 2014
Remember the dot-com days of Webvan and Pets.com? We took traditional businesses and gave then an online presence. Rapidly acquiring a large customer base was the sole goal of many dot-coms. “If we can get enough users, we can easily figure out how to monetize it.” And all of this made perfect sense expressed in dollars and cents. I know people who melted down Yahoo Finance’s servers by checking for their favourite stocks prices throughout the day, calculating their (paper) net worth in real time. If you were not part of this madness, you were certainly considered stupid.
But then on March 10, 2000, the perspective changed. Suddenly it became clear that this was really a bubble. Without having real profits (or even revenue/cash-flow), it was really just a house of cards. In hindsight, the entire dot-com burst made perfect sense. But why wasn’t this obvious to everyone (including me) to start with?
In complex adaptive system, the causality is retrospectively coherent. .i.e. hindsight does not lead to foresight. When we look back at the events, we can (relatively) easily construct a theory to explain the rationale behind the occurrence of these events. In fact, when we look back, the reasons are so obvious that one can easily be fooled into believing that “Only if we spend more time, carefully analysing and thinking through the situation at hand, we can completely avoid unwanted events in future.” Yet, time and again, we’ve always been caught by surprise and it almost appears to be impossible to predict such events ahead of time. Call it the Black Swan effect or whatever name you fancy.
This effect gives rise to a classic management dilemma – Predictability Paradox(pdf). In the zeal to improve the effectiveness and reliability of software development, managers institutionalise practices that unfortunately decrease, rather than increase, the predictability of the product’s success. Most companies spend an awful lot of effort and money to analyse the past, derive patterns and best practices, set targets and create processes to prevent past failure and produce ideal future goals. If software development was highly structured, if we had a stable environment and we had a good data points from million other projects, this approach might work. But for software development, which is a creative-problem solving domain, with high levels of uncertainty and each project having an unique context, these techniques (best practices) are rather dangerous.
In our domain,
- We need to break the vague problem down into small safe-fail experiments.
- Then execute each experiment in short iterative and incremental cycles.
- We need to focus on tight feedback loops, which will help us adapt & co-evolve the system. (We cannot be stuck with analysis paralysis.)
- We need to probe the system with experiments and find emergent practices.
- And then apply these practices in a given context, for a short duration.
- Speed and Sustainability are extremely important factors.
This is what I mean when I say “Action Precedes Clarity”.
Posted in Agile, Analysis, Cognitive Science, Experiment, Lean Startup | 3 Comments »
Saturday, October 12th, 2013
May be I don’t understand the Lean-startup lingo, but to me a MVP has always been about finding the cheapest, safest way to validate your product hypothesis. Sometimes you might need to build a miniature version of your product or service to test your hypothesis and obtain validated learning. But it is not always necessary or even desirable to build something.
Let’s zoom out for a minute. Let’s say you have an idea or a vision for a product or a service. You devise a series of possible strategies you could use to fulfill your vision. However it is important to acknowledge that each of your strategy is based on a list of hypothesis, which needs to be validated using a series of cheap, safe-fail experiments (via MVPs) to obtain validated learning. Then based on real data, we pivot or persist the direction of the vision. Either ways, you need to constantly keep running a series of experiments with real fast feedback cycles to calibrate/validate your progress/direction.
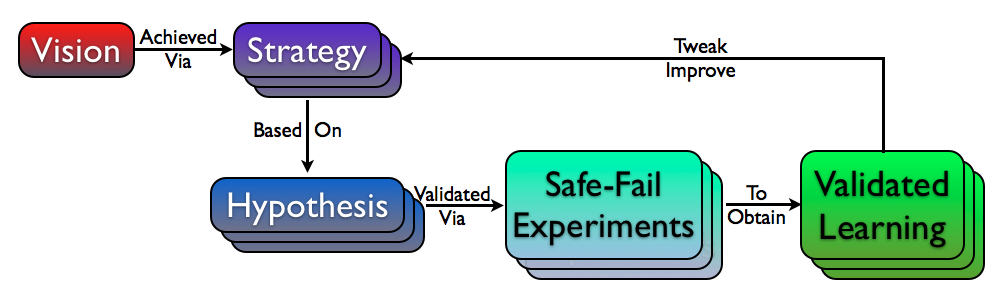
MVP is a safe-fail experiment. The best MVPs are those which give you maximum validated learning for minimum investment (time, effort & opportunity cost.)
For example:
- NeedFeed used a GreaseMonkey script to quickly validate their hypothesis about their social purchasing app on Facebook – http://vimeo.com/24749599
- At EdventureLabs we used presentations to create quick videos to test different learning techniques and their retention power with kids.
- Or we used dummy meters to validate the business model of an energy company, which wanted to build energy saving products for rural India. We visited a few farmers and small factories, explained how the device (dummy meter) would save them 50% on electricity bill each month. We quickly discovered that our business model was flawed and surprisingly we co-created a better model. Also through this process we learned about certain key concerns these folks had which required a very different conceptualization of the product.
Your ability to quickly (almost on the fly) tweak a little parameters and quickly test a corollary hypothesis is another very important characteristic of an MVP. This is extremely important because when you go out there in the field to run your experiment, in the moment, you might find new data or ideas which might need to be validated to solidify your validated learning. If you have to make code changes and deploy stuff, it might not be easy for you to test new hypothesis, right then and there. Which is very important IMHO.
Next time you think of a MVP, think about a cheap, safe-fail experiment you can run to validate your hypothesis.
Note: Its important to distinguish MVP from Features Stubs. Feature stubs are also a quick way to validate your hypothesis, however they are mostly applicable once you have a product and want to validate how useful certain feature might be.
For example: Recently, I wanted to test if liking a comment on the Agile India Submission system is a feature people would find useful.

I added a like button which would simply show an alert message saying “Coming Soon..”. Using Google Analytics, I was able to measure that out of 36,000 impressions, only 6 people clicked on the Like button. A cheap way to validate my hypothesis. But this does not affect my product strategy and hence its different from MVP.
Posted in Lean Startup | No Comments »
Sunday, July 8th, 2012
| A |
Acceptance Criteria/Test, Automation, A/B Testing, Adaptive Planning, Appreciative inquiry |
| B |
Backlog, Business Value, Burndown, Big Visible Charts, Behavior Driven Development, Bugs, Build Monkey, Big Design Up Front (BDUF) |
| C |
Continuous Integration, Continuous Deployment, Continuous Improvement, Celebration, Capacity Planning, Code Smells, Customer Development, Customer Collaboration, Code Coverage, Cyclomatic Complexity, Cycle Time, Collective Ownership, Cross functional Team, C3 (Complexity, Coverage and Churn), Critical Chain |
| D |
Definition of Done (DoD)/Doneness Criteria, Done Done, Daily Scrum, Deliverables, Dojos, Drum Buffer Rope |
| E |
Epic, Evolutionary Design, Energized Work, Exploratory Testing |
| F |
Flow, Fail-Fast, Feature Teams, Five Whys |
| G |
Grooming (Backlog) Meeting, Gemba |
| H |
Hungover Story |
| I |
Impediment, Iteration, Inspect and Adapt, Informative Workspace, Information radiator, Immunization test, IKIWISI (I’ll Know It When I See It) |
| J |
Just-in-time |
| K |
Kanban, Kaizen, Knowledge Workers |
| L |
Last responsible moment, Lead time, Lean Thinking |
| M |
Minimum Viable Product (MVP), Minimum Marketable Features, Mock Objects, Mistake Proofing, MOSCOW Priority, Mindfulness, Muda |
| N |
Non-functional Requirements, Non-value add |
| O |
Onsite customer, Opportunity Backlog, Organizational Transformation, Osmotic Communication |
| P |
Pivot, Product Discovery, Product Owner, Pair Programming, Planning Game, Potentially shippable product, Pull-based-planning, Predictability Paradox |
| Q |
Quality First, Queuing theory |
| R |
Refactoring, Retrospective, Reviews, Release Roadmap, Risk log, Root cause analysis |
| S |
Simplicity, Sprint, Story Points, Standup Meeting, Scrum Master, Sprint Backlog, Self-Organized Teams, Story Map, Sashimi, Sustainable pace, Set-based development, Service time, Spike, Stakeholder, Stop-the-line, Sprint Termination, Single Click Deploy, Systems Thinking, Single Minute Setup, Safe Fail Experimentation |
| T |
Technical Debt, Test Driven Development, Ten minute build, Theme, Tracer bullet, Task Board, Theory of Constraints, Throughput, Timeboxing, Testing Pyramid, Three-Sixty Review |
| U |
User Story, Unit Tests, Ubiquitous Language, User Centered Design |
| V |
Velocity, Value Stream Mapping, Vision Statement, Vanity metrics, Voice of the Customer, Visual controls |
| W |
Work in Progress (WIP), Whole Team, Working Software, War Room, Waste Elimination |
| X |
xUnit |
| Y |
YAGNI (You Aren’t Gonna Need It) |
| Z |
Zero Downtime Deployment, Zen Mind |
Posted in Agile | No Comments »
Sunday, March 6th, 2011
Recently TV tweeted saying:
Is “measure twice, cut once” an #agile value? Why shouldn’t it be – it is more fundamental than agile.
To which I responded saying:
“measure twice, cut once” makes sense when cost of a mistake & rework is huge. In software that’s not the case if done in small, safe steps. A feedback centric method like #agile can help reduce the cost of rework. Helping you #FailFast and create opportunities for #SafeFailExperiements. (Extremely important for innovation.)
To step back a little, the proverb “measure twice and cut once” in carpentry literally mean:
“One should double-check one’s measurements for accuracy before cutting a piece of wood; otherwise it may be necessary to cut again, wasting time and material.”
Speaking more figuratively it means “Plan and prepare in a careful, thorough manner before taking action.”
Unfortunately many software teams literally take this advice as
“Let’s spend a few solid months carefully planning, estimating and designing software upfront, so we can avoid rework and last minute surprise.”
However after doing all that, they realize it was not worth it. Best case they delivered something useful to end users with about 40% rework. Worst case they never delivered or delivered something buggy that does not meet user’s needs. But what about the opportunity cost?
Why does this happen?
Humphrey’s law says: “Users will not know exactly what they want until they see it (may be not even then).”
So how can we plan (measure twice) when its not clear what exactly our users want (even if we can pretend that we understand our user’s needs)?
How can we plan for uncertainty?
IMHO you can’t plan for uncertainty. You respond to uncertainty by inspecting and adapting. You learn by deliberately conducting many safe-fail experiments.
What is Safe-Fail Experimentation?
Safe-fail experimentation is a learning and problem solving technique which emphasizes on conducting many simultaneous, small, controlled experiments with small variations. Since these are small controlled experiments, failure is an expected & acceptable outcome.
In the software world, spiking, low-fi-prototypes, set-based design, continuous deployment, A/B Testing, etc. are all forms of safe-fail experiments.
Generally we like to start with something really small (but end-to-end) and rapidly build on it using user feedback and personal experience. Embracing Simplicity (“maximizing the amount of work not done”) is critical as well. You frequently cut small pieces, integrate the whole and see if its aligned with user’s needs. If not, the cost of rework is very small. Embrace small #SafeFail experiments to really innovate.
Or as Kerry says:
“Perhaps the fundamental point is that in software development the best way of measuring is to cut.”
Also strongly recommend you read the Basic principles of safe-fail experimentation.
Posted in Agile, Continuous Deployment, Planning | No Comments »
|

