`
| |
|
Friday, October 3rd, 2014
Many teams suffer daily due to slow CI builds. The teams certainly realise the pain, but don’t necessarily take any corrective action. The most common excuse is we don’t have time or we don’t think it can get better than this.

Following are some key principles, I’ve used when confronted with long running builds:
- Focus on the Bottlenecks – Profile your builds to find the real culprits. Fixing them will help the most. IMHE I’ve seen the 80-20 rule apply here. Fixing 20% of the bottlenecks will give you 80% gain in speed.
- Divide and Conquer – Turn large monolithic builds into smaller, more focused builds. This would typically lead to restructuring your project into smaller modules or projects, which is a good version control practice anyway. Also most CI servers support a build pipeline, which will help you hookup all these smaller builds together.
- Turn Sequential Tasks to Parallel Tasks – By breaking your builds into smaller builds, you can now run them in parallel. You can also distribute the tasks across multiple slave machines. Also consider running your tests in parallel. Many static analysis tools can run in parallel.
- Reuse – Don’t create/start from scratch if you can avoid it. For ex: have pre-compiled code (jars) for dependent code instead of building it every time, esp. if it rarely changes. Set up your target env as a VM and keep it ready. Use a database dump for your seed data, instead of building it from an empty DB every time. Many times we use incremental compile/build, instead of clean builds.
- Avoid/Minimise IO (Disk & Network) – IOs can be a huge bottleneck. Turn down logging when running your builds. Preference using an in-process & in-memory DB, consider tmpfs for in-memory file system.
- Fail Fast – We want our builds to give us fast feedback. Hence its very important to prioritise your build tasks based on what is most likely to fail first. In fact long back we had started a project called ProTest, which helps you prioritise your tests on which test is most likely to fail.
- Push unnecessary stuff to a separate build – Things like JavaDocs can be done nightly
- Once and Only Once – avoid unnecessary duplication in steps. For ex: copying src files or jars to another location, creating a new Jenkins workspace every build, empty DB creation, etc.
- Reduce Noise – remove unnecessary data and file. Work on a minimal, yet apt set. Turn down logging levels.
- Time is Money -I guess I’m stating the obvious. But using newer, faster tools is actually cheaper. Moving from CVS/SVN to Git can speed up your build, newer testing frameworks are faster. Also Hardware is getting cheaper day by day, while developer’s cost is going up day by day. Invest in good hardware like SSD, Faster Multi-core CPUs, better RAM, etc. It would be way cheaper than your team waiting for the builds.
- Profile, Understand and Configure – Ignorance can be fatal. When it comes to build, you must profile your build to find the bottleneck. Go deeper to understand what is going on. And then based on data, configure your environment. For ex: setting the right OS parameters, set the right compiler flags can make a noticeable difference.
- Keep an Open Mind – Many times, you will find the real culprits might be some totally unrelated part of your environment. Many times we also find poorly written code which can slow things down. One needs to keep an open mind.
Are there any other principles you’ve used?
BTW Ashish and I plan to present this topic at the upcoming Agile Pune 2014 Conference. Would love to see you there.
Posted in Continuous Deployment, Tips | 4 Comments »
Tuesday, March 19th, 2013
It’s easy to speak of test-driven development as if it were a single method, but there are several ways to approach it. In my experience, different approaches lead to quite different solutions.
In this hands-on workshop, with the help of some concrete examples, I’ll demonstrate the different styles and more importantly what goes into the moment of decision when a test is written? And why TDDers make certain choices. The objective of the session is not to decide which approach is best, rather to highlight various different approaches/styles of practicing test-driven development.
By the end of this session, you will understand how TTDers break down a problem before trying to solve it. Also you’ll be exposed to various strategies or techniques used by TDDers to help them write the first few tests.
Posted in Agile, Design, Programming, Testing | No Comments »
Tuesday, March 19th, 2013
Recently at the Agile India 2013 Conference I ran an introductory workshop on Behavior Driven Development. This workshop offered a comprehensive, hands-on introduction to behavior driven development via an interactive-demo.
Over the past decade, eXtreme Programming practices like Test-Driven Development (TDD) and Behaviour Driven Development (BDD) have fundamentally changed software development processes and inherently how engineers work. Practitioners claim that it has helped them significantly improve their collaboration with business, development speed, design & code quality and responsiveness to changing requirements. Software professionals across the board, from Internet startups to medical device companies to space research organizations, today have embraced these practices.
This workshop explores the foundations of TDD & BDD with the help of various patterns, strategies, tools and techniques.
Posted in Agile, Continuous Deployment, Design, Programming | No Comments »
Tuesday, March 19th, 2013
As more and more companies are moving to the Cloud, they want their latest, greatest software features to be available to their users as quickly as they are built. However there are several issues blocking them from moving ahead.
One key issue is the massive amount of time it takes for someone to certify that the new feature is indeed working as expected and also to assure that the rest of the features will continuing to work. In spite of this long waiting cycle, we still cannot assure that our software will not have any issues. In fact, many times our assumptions about the user’s needs or behavior might itself be wrong. But this long testing cycle only helps us validate that our assumptions works as assumed.
How can we break out of this rut & get thin slices of our features in front of our users to validate our assumptions early?
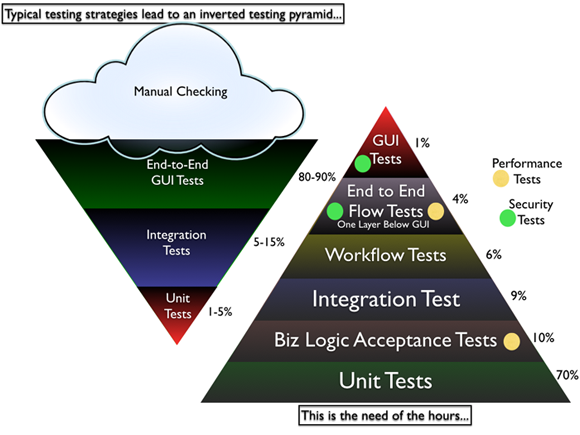
Most software organizations today suffer from what I call, the “Inverted Testing Pyramid” problem. They spend maximum time and effort manually checking software. Some invest in automation, but mostly building slow, complex, fragile end-to-end GUI test. Very little effort is spent on building a solid foundation of unit & acceptance tests.
This over-investment in end-to-end tests is a slippery slope. Once you start on this path, you end up investing even more time & effort on testing which gives you diminishing returns.
In this session Naresh Jain will explain the key misconceptions that has lead to the inverted testing pyramid approach being massively adopted, main drawbacks of this approach and how to turn your organization around to get the right testing pyramid.
Posted in Agile, Continuous Deployment, Deployment, Testing | No Comments »
Sunday, July 8th, 2012
| A |
Acceptance Criteria/Test, Automation, A/B Testing, Adaptive Planning, Appreciative inquiry |
| B |
Backlog, Business Value, Burndown, Big Visible Charts, Behavior Driven Development, Bugs, Build Monkey, Big Design Up Front (BDUF) |
| C |
Continuous Integration, Continuous Deployment, Continuous Improvement, Celebration, Capacity Planning, Code Smells, Customer Development, Customer Collaboration, Code Coverage, Cyclomatic Complexity, Cycle Time, Collective Ownership, Cross functional Team, C3 (Complexity, Coverage and Churn), Critical Chain |
| D |
Definition of Done (DoD)/Doneness Criteria, Done Done, Daily Scrum, Deliverables, Dojos, Drum Buffer Rope |
| E |
Epic, Evolutionary Design, Energized Work, Exploratory Testing |
| F |
Flow, Fail-Fast, Feature Teams, Five Whys |
| G |
Grooming (Backlog) Meeting, Gemba |
| H |
Hungover Story |
| I |
Impediment, Iteration, Inspect and Adapt, Informative Workspace, Information radiator, Immunization test, IKIWISI (I’ll Know It When I See It) |
| J |
Just-in-time |
| K |
Kanban, Kaizen, Knowledge Workers |
| L |
Last responsible moment, Lead time, Lean Thinking |
| M |
Minimum Viable Product (MVP), Minimum Marketable Features, Mock Objects, Mistake Proofing, MOSCOW Priority, Mindfulness, Muda |
| N |
Non-functional Requirements, Non-value add |
| O |
Onsite customer, Opportunity Backlog, Organizational Transformation, Osmotic Communication |
| P |
Pivot, Product Discovery, Product Owner, Pair Programming, Planning Game, Potentially shippable product, Pull-based-planning, Predictability Paradox |
| Q |
Quality First, Queuing theory |
| R |
Refactoring, Retrospective, Reviews, Release Roadmap, Risk log, Root cause analysis |
| S |
Simplicity, Sprint, Story Points, Standup Meeting, Scrum Master, Sprint Backlog, Self-Organized Teams, Story Map, Sashimi, Sustainable pace, Set-based development, Service time, Spike, Stakeholder, Stop-the-line, Sprint Termination, Single Click Deploy, Systems Thinking, Single Minute Setup, Safe Fail Experimentation |
| T |
Technical Debt, Test Driven Development, Ten minute build, Theme, Tracer bullet, Task Board, Theory of Constraints, Throughput, Timeboxing, Testing Pyramid, Three-Sixty Review |
| U |
User Story, Unit Tests, Ubiquitous Language, User Centered Design |
| V |
Velocity, Value Stream Mapping, Vision Statement, Vanity metrics, Voice of the Customer, Visual controls |
| W |
Work in Progress (WIP), Whole Team, Working Software, War Room, Waste Elimination |
| X |
xUnit |
| Y |
YAGNI (You Aren’t Gonna Need It) |
| Z |
Zero Downtime Deployment, Zen Mind |
Posted in Agile | No Comments »
Tuesday, November 1st, 2011
“Release Early, Release Often” is a proven mantra, but what happens when you push this practice to it’s limits? .i.e. deploying latest code changes to the production servers every time a developer checks-in code?
At Industrial Logic, developers are deploying code dozens of times a day, rapidly responding to their customers and reducing their “code inventory”.
This talk will demonstrate our approach, deployment architecture, tools and culture needed for CD and how at Industrial Logic, we gradually got there.
Process/Mechanics
This will be a 60 mins interactive talk with a demo. Also has a small group activity as an icebreaker.
Key takeaway: When we started about 2 years ago, it felt like it was a huge step to achieve CD. Almost a all or nothing. Over the next 6 months we were able to break down the problem and achieve CD in baby steps. I think that approach we took to CD is a key take away from this session.
Talk Outline
- Context Setting: Need for Continuous Integration (3 mins)
- Next steps to CI (2 mins)
- Intro to Continuous Deployment (5 mins)
- Demo of CD at Freeset (for Content Delivery on Web) (10 mins) – a quick, live walk thru of how the deployment and servers are set up
- Benefits of CD (5 mins)
- Demo of CD for Industrial Logic’s eLearning (15 mins) – a detailed walk thru of our evolution and live demo of the steps that take place during our CD process
- Zero Downtime deployment (10 mins)
- CD’s Impact on Team Culture (5 mins)
- Q&A (5 mins)
Target Audience
- CTO
- Architect
- Tech Lead
- Developers
- Operations
Context
Industrial Logic’s eLearning context? number of changes, developers, customers , etc…?
Industrial Logic’s eLearning has rich multi-media interactive content delivered over the web. Our eLearning modules (called Albums) has pictures & text, videos, quizes, programming exercises (labs) in 5 different programming languages, packing system to validate & produce the labs, plugins for different IDEs on different platforms to record programming sessions, analysis engine to score student’s lab work in different languages, commenting system, reporting system to generate different kind of student reports, etc.
We have 2 kinds of changes, eLearning platform changes (requires updating code or configuration) or content changes (either code or any other multi-media changes.) This is managed by 5 distributed contributors.
On an average we’ve seen about 12 check-ins per day.
Our customers are developers, managers and L&D teams from companies like Google, GE Energy, HP, EMC, Philips, and many other fortune 100 companies. Our customers have very high expectations from our side. We have to demonstrate what we preach.
Learning outcomes
- General Architectural considerations for CD
- Tools and Cultural change required to embrace CD
- How to achieve Zero-downtime deploys (including databases)
- How to slice work (stories) such that something is deployable and usable very early on
- How to build different visibility levels such that new/experimental features are only visible to subset of users
- What Delivery tests do
- You should walk away with some good ideas of how your company can practice CD
Slides from Previous Talks
Posted in Agile, Continuous Deployment, Deployment, Lean Startup, Product Development, Testing, Tools | No Comments »
Monday, April 18th, 2011
Building on top of my previous blog entry: Version Control Branching (extensively) Considered Harmful
I always discourage teams from preemptively branching a release candidate and then splitting their team to harden the release while rest of the team continues working on next release features.
My reasoning:
- Increases the work-in-progress and creates a lot of planning, management, version-control, testing, etc. overheads.
- In the grand scheme of things, we are focusing on resource utilization, but the throughput of the overall system is actually reducing.
- During development, teams get very focused on churning out features. Subconsciously they know there will be a hardening/optimization phase at the end, so they tend to cut corners for short-term speed gains. This attitude had a snowball effect. Overall encourages a “not-my-problem” attitude towards quality, performance and overall usability.
- The team (developers, testers and managers) responsible for hardening the release have to work extremely hard, under high pressure causing them to burn-out (and possibly introducing more problems into the system.) They have to suffer for the mistakes others have done. Does not seem like a fair system.
- Because the team is under high pressure to deliver the release, even though they know something really needs to be redesigned/refactored, they just patch it up. Constantly doing this, really creates a big ball of complex mud that only a few people understand.
- Creates a “Knowledge/Skill divide” between the developers and testers of the team. Generally the best (most trusted and knowledgable) members are pick up to work on the release hardening and performance optimization. They learn many interesting things while doing this. This newly acquired knowledge does not effectively get communicate back to other team members (mostly developers). Others continue doing what they used to do (potentially wrong things which the hardening team has to fix later.)
- As releases pass by, there are fewer and fewer people who understand the overall system and only they are able to effectively harden the project. This is a huge project risk.
- Over a period of time, every new release needs more hardening time due to the points highlighted above. This approach does not seem like a good strategy of getting out of the problem.
If something hurts, do it all the time to reduce the pain and get better at it.
Hence we should build release hardening as much as possible into the routine everyday work. If you still need hardening at the end, then instead of splitting the teams, we should let the whole swamp on making the release.
Also usually I notice that if only a subset of the team can effectively do the hardening, then its a good indication that the team is over-staffed and that might be one of the reasons for many problems in the first place. It might be worth considering down-sizing your team to see if some of those problems can be addressed.
Posted in Agile, Continuous Deployment, Learning, Organizational, Planning, Programming, Testing | No Comments »
Sunday, April 17th, 2011
Better productivity and collaboration via
improved feedback and high-quality information.

- Encourages an Evolutionary Design and Continuous Improvement culture
- On complex projects, forces a nicely decoupled design such that each modules can be independently tested. Also ensures that in production you can support different versions of each module.
- Team takes shared ownership of their development and build process
- The source control trunk is in an always-working-state (avoid multiple branch issues)
- No developer is blocked because they can’t get stable code
- Developers break down work into small end-to-end, testable slices and checks-in multiple times a day
- Developers are up-to date with other developer changes
- Team catches issues at the source and avoids last minute integration nightmares
- Developers get rapid feedback once they check-in their code
- Builds are optimized and parallelized for speed
- Builds are incremental in nature (not big bang over-night builds)
- Builds run all the automated tests (may be staged) to give realistic feedback
- Captures and visualizes build results and logs very effectively
- Display various source code quality metrics trends
- Code coverage, cyclomatic complexity, coding convention violation, version control activity, bug counts, etc.
- Influence the right behavior in the team by acting as Information Radiator in the team area
- Provide clear visual feedback about the build status
- Developers ask for an easy way to run and debug builds locally (or remotely)
- Broken builds are rare. However broken builds are rapidly fixed by developers
- Build results are intelligently archived
- Easy navigation between various build versions
- Easily visualization and comparison of the change sets
- Large monolithic builds are broken into smaller, self contained builds with a clear build promotion process
- Complete traceability exists
- Version Control, Project & Requirements Managements tool, Bug Tracking and Build system are completely integrated.
- CI page becomes the project dashboard for everyone (devs, testers, managers, etc.).
Any other impact you think is worth highlighting?
Posted in Agile, Continuous Deployment, Metrics, Organizational | No Comments »
Tuesday, February 1st, 2011
As more and more companies are moving to the Cloud, they want their latest, greatest software features to be available to their users as quickly as they are built. However there are several issues blocking them from moving ahead.
One key issue is the massive amount of time it takes for someone to certify that the new feature is indeed working as expected and also to assure that the rest of the features will continuing to work. In spite of this long waiting cycle, we still cannot assure that our software will not have any issues. In fact, many times our assumptions about the user’s needs or behavior might itself be wrong. But this long testing cycle only helps us validate that our assumptions works as assumed.
How can we break out of this rut & get thin slices of our features in front of our users to validate our assumptions early?
Most software organizations today suffer from what I call, the “Inverted Testing Pyramid” problem. They spend maximum time and effort manually checking software. Some invest in automation, but mostly building slow, complex, fragile end-to-end GUI test. Very little effort is spent on building a solid foundation of unit & acceptance tests.
This over-investment in end-to-end tests is a slippery slope. Once you start on this path, you end up investing even more time & effort on testing which gives you diminishing returns.
They end up with majority (80-90%) of their tests being end-to-end GUI tests. Some effort is spent on writing so-called “Integration test” (typically 5-15%.) Resulting in a shocking 1-5% of their tests being unit/micro tests.
Why is this a problem?
- The base of the pyramid is constructed from end-to-end GUI test, which are famous for their fragility and complexity. A small pixel change in the location of a UI component can result in test failure. GUI tests are also very time-sensitive, sometimes resulting in random failure (false-negative.)
- To make matters worst, most teams struggle automating their end-to-end tests early on, which results in huge amount of time spent in manual regression testing. Its quite common to find test teams struggling to catch up with development. This lag causes many other hard-development problems.
- Number of end-to-end tests required to get a good coverage is much higher and more complex than the number of unit tests + selected end-to-end tests required. (BEWARE: Don’t be Seduced by Code Coverage Numbers)

- Maintain a large number of end-to-end tests is quite a nightmare for teams. Following are some core issues with end-to-end tests:
- It requires deep domain knowledge and high technical skills to write quality end-to-end tests.
- They take a lot of time to execute.
- They are relatively resource intensive.
- Testing negative paths in end-to-end tests is very difficult (or impossible) compared to lower level tests.
- When an end-to-end test fails, we don’t get pin-pointed feedback about what went wrong.
- They are more tightly coupled with the environment and have external dependencies, hence fragile. Slight changes to the environment can cause the tests to fail. (false-negative.)
- From a refactoring point of view, they don’t give the same comfort feeling to developers as unit tests can give.
Again don’t get me wrong. I’m not suggesting end-to-end integration tests are a scam. I certainly think they have a place and time.
Imagine, an automobile company building an automobile without testing/checking the bolts, nuts all the way up to the engine, transmission, breaks, etc. And then just assembling the whole thing somehow and asking you to drive it. Would you test drive that automobile? But you will see many software companies using this approach to building software.
What I propose and help many organizations achieve is the right balance of end-to-end tests, acceptance tests and unit tests. I call this “Inverting the Testing Pyramid.” [Inspired by Jonathan Wilson’s book called Inverting The Pyramid: The History Of Football Tactics].
In a later blog post I can quickly highlight various tactics used to invert the pyramid.
Update: I recently came across Alister Scott’s blog on Introducing the software testing ice-cream cone (anti-pattern). Strongly suggest you read it.
Posted in Agile, Design, Testing | 14 Comments »
|